

In a world where data is increasingly seen as a valuable resource, protecting personal information is becoming increasingly important. Organizations working with sensitive data are challenged to protect it while simultaneously capturing its value. This is where two crucial concepts of data masking come into play: data anonymization and pseudonymization . While both methods aim to protect privacy, they differ fundamentally in approach and purpose.
In this blog, we dive deeper into the differences between both concepts. Whether you are a data professional or just interested in how your data is protected, this blog provides valuable insights into the complex but fascinating world of data privacy.
Key Takeways
- Pseudonymization involves transforming personal data so that it is no longer directly traceable to a person.
- Pseudonymization requires that the original data be retained. If the original data is destroyed or re-identification is impossible, pseudonymized data will be transformed into anonymized data.
- Anonymizing personal data is adjusting data so that it can no longer be used to identify an individual. Anonymization is irreversible.
- For the GDPR, pseudonymized data is still personal data, anonymized data is not.
- The difference between anonymizing and pseudonymizing is that pseudonymized data can be made insightful again and anonymized data cannot.
Example masked data
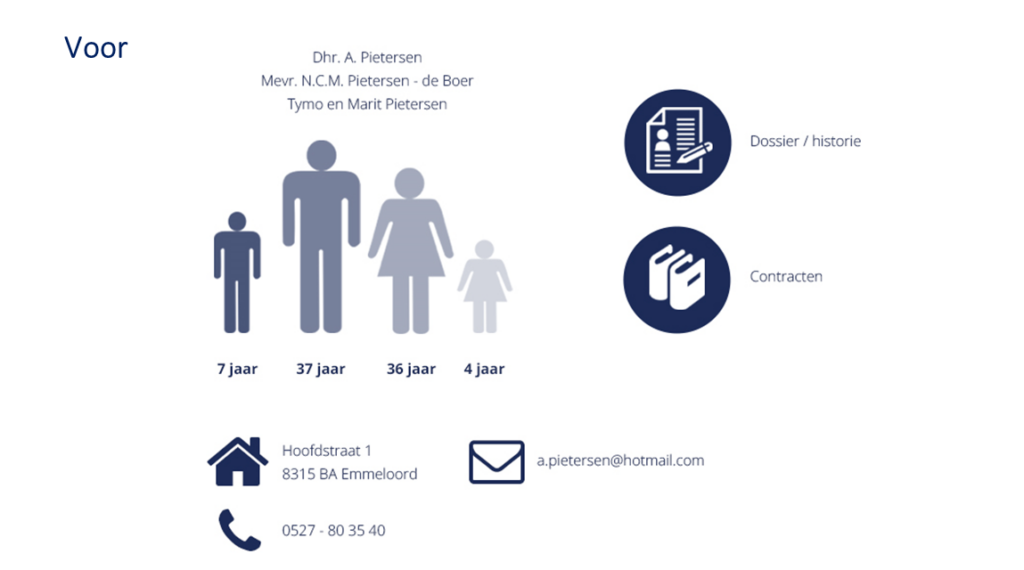
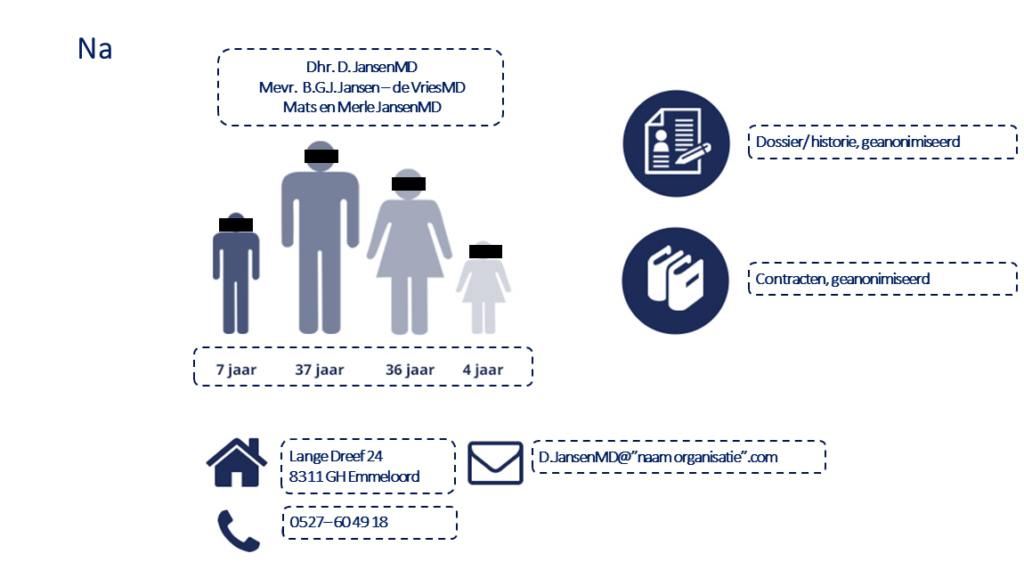
Pseudonymization of personal data
Pseudonymisation of personal data involves transforming data so that it can no longer be directly traced back to a person. Directly identifiable elements, such as a name, are removed.
With pseudonymized data, the modified dataset is stored separately from the original data. With pseudonymized data, it is important that the original data is retained. If the data is destroyed for any reason or re-identification proves impossible, the data will be changed into anonymized data.
When pseudonymised data is shared with third parties or stored within the organisation, it must still be treated as personal data. Even though it is not immediately clear who it concerns.
You can see data pseudonymization as a security measure. It reduces the privacy risk of data subjects and organizations that process this data.
What are the benefits of pseudonymized data?
- The chance of misuse of pseudonymised data in data leaks is smaller. If this data ends up on the street, it can only be traced back to a person if the original data is also known.
- Processing pseudonymized data is more likely to be permitted than “ordinary” personal data.
- Using personal data for a purpose other than that for which it was originally intended is more likely to be permitted. As is processing special personal data and archiving data for the general interest.
Anonymizing personal data
Anonymizing personal data is also called data masking. Data masking is a method that ensures that data can no longer be used to identify a person. Anonymizing data is irreversible. According to the GDPR, anonymized data is therefore no longer personal data. Anonymizing data is valuable, for example, when an organization wants to use data for statistical purposes, but it is not important to trace this data back to a person.
Anonymizing data should be done by an authorized person and within the applicable rules.
Benefits of anonymizing data
- When there is a data breach within your organization it does not cause problems because the data is no longer considered personal data.
- Data can be kept without problem.
- Data can be used without problem for other purposes such as statistical or analytical purposes.
What is the difference between data anonymization and pseudonymization?
The big difference between anonymization and pseudonymization is that pseudonymized data can be made visible again and can therefore lead to a person. Anonymization is irreversible.
With pseudonymization, anonymized data can be made visible again with the right key. With the right key, it is then also possible to trace it back to a natural person. With anonymization, it is no longer possible to retrieve the original data. The encryption of this data is irreversible.
In addition, pseudonymized data is still personal data for the GDPR and the GDPR rules still apply. Anonymized data is no longer personal data for the GDPR, so no GDPR rules apply.
Is your organization about to review its strategy regarding the processing of personal data? Please contact us without obligation. We are happy to help you with the pseudonymization or anonymization of sensitive data in your database or documents.
Our solutions
Many of our clients are aware that they receive, store, retain and process documents in which personal data is visible to all or much of the organization. Meanwhile, these customers “cleaned up” by letting DataFactory or FileFactory software do its work. Curious about the possibilities? If so, please contact us.