

In een wereld waarin data steeds meer als een waardevolle hulpbron wordt beschouwd, wordt de bescherming van persoonlijke informatie steeds belangrijker. Organisaties die met gevoelige gegevens werken, staan voor de uitdaging om deze te beschermen, terwijl ze tegelijkertijd de waarde ervan willen benutten. Hier komen twee cruciale concepten van data masking om de hoek kijken: data anonimiseren en pseudonimiseren. Hoewel beide methoden gericht zijn op het beschermen van de privacy, verschillen ze fundamenteel in aanpak en doel.
In deze blog duiken we dieper in de verschillen tussen beide concepten. Of u nu een data professional bent of gewoon geïnteresseerd in hoe uw gegevens worden beschermd, deze blog biedt waardevolle inzichten in de complexe maar fascinerende wereld van dataprivacy.
Key Takeways
- Pseudonimiseren houdt in het transformeren van persoonsgegevens waardoor deze niet meer direct herleidbaar zijn naar een persoon.
- Bij pseudonimiseren moet de originele data bewaard blijven. Is de originele data vernietigd of is re-identificatie onmogelijk, dan verandert gepseudonimiseerde data in geanonimiseerde data.
- Het anonimiseren van persoonsgegevens is het aanpassen van gegevens zodat deze niet meer gebruikt kunnen worden om een persoon te identificeren. Anonimiseren is onomkeerbaar.
- Voor de AVG zijn gepseudonimiseerde gegevens nog steeds persoonsgegevens, geanonimiseerde gegevens niet.
- Het verschil tussen anonimiseren en pseudonimiseren is dat gepseudonimiseerde gegevens weer inzichtelijk gemaakt kunnen worden en geanonimiseerde gegevens niet.
Voorbeeld gemaskeerde data
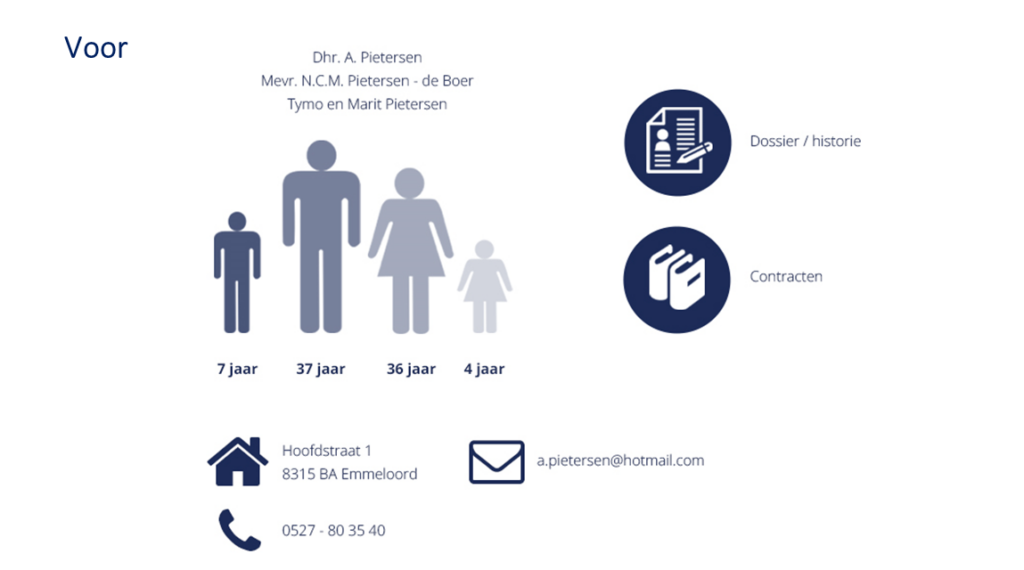
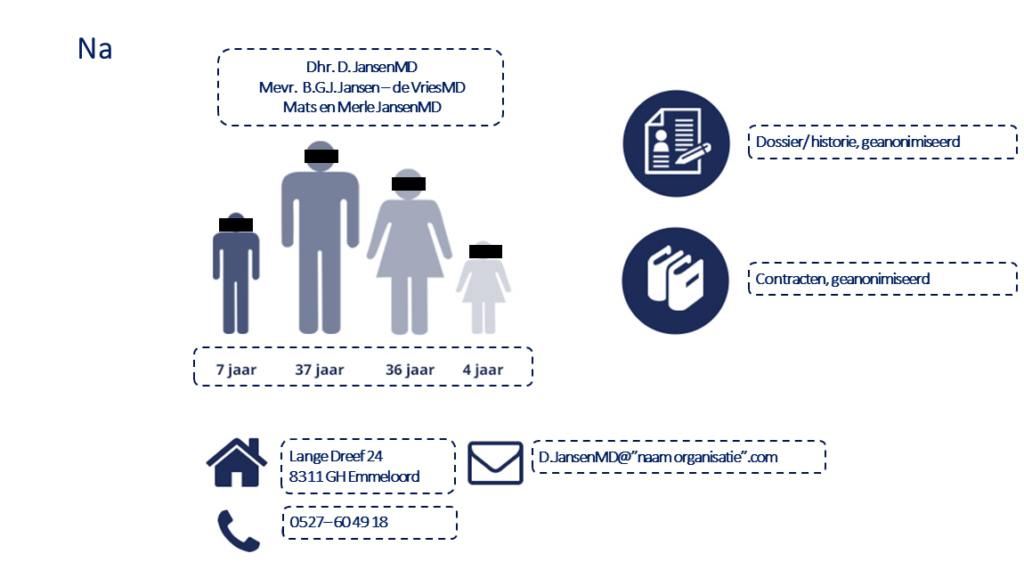
Pseudonimiseren van persoonsgegevens
Het pseudonimiseren van persoonsgegevens houdt in het transformeren van gegevens waardoor deze niet meer direct herleidbaar zijn naar een persoon. Hierbij worden direct identificeerbare elementen, zoals een naam, weggehaald.
Bij gepseudonimiseerde data wordt de aangepaste dataset apart bewaard van de originele data. Bij gepseudonimiseerde data is het van belang dat de originele data bewaard blijft. Mocht de data om welke reden dan ook vernietigd worden of re-identificatie blijkt onmogelijk, dan verandert de data in geanonimiseerde data.
Wanneer gepseudonimiseerde data wordt gedeeld met derden of wordt opgeslagen binnen de organisatie, moet deze alsnog behandeld worden als zijnde persoonsgegevens. Ondanks dat het niet direct duidelijk is om wie het gaat.
Je kunt data pseudonimiseren zien als een beveiligingsmaatregel. Het verlaagt het privacy risico van betrokkenen en organisaties die deze gegevens verwerken.
Wat zijn de voordelen van gepseudonimiseerde gegevens?
- De kans op misbruik van gepseudonimiseerde gegevens bij datalekken is kleiner. Als deze data op straat komt te liggen, is dit enkel naar een persoon te herleiden wanneer ook de originele data bekend is.
- Het verwerken van gepseudonimiseerde gegevens is eerder toegestaan dan ‘gewone’ persoonsgegevens.
- Het gebruiken van persoonsgegevens voor een ander doel dan waar ze vooraf voor waren bedoeld is eerder toegestaan. Net zoals het verwerken van bijzondere persoonsgegevens en het archiveren van de gegevens voor algemeen belang.
Anonimiseren van persoonsgegevens
Het anonimiseren van persoonsgegevens wordt ook wel datamaskering genoemd. Datamaskering is een methode die ervoor zorgt dat gegevens niet meer gebruikt kunnen worden om een persoon te identificeren. Het anonimiseren van gegevens is onomkeerbaar. Volgens de AVG zijn geanonimiseerde gegevens hierdoor ook geen persoonsgegevens meer. Het anonimiseren van gegevens is bijvoorbeeld waardevol wanneer een organisatie gegevens wil gebruiken voor statistische doeleinden, maar het niet van belang is om deze gegevens naar een persoon te herleiden.
Het anonimiseren van gegevens dient te gebeuren door een geautoriseerd persoon en binnen de daarvoor geldende regels.
Voordelen van anonimiseren van gegevens
- Wanneer er een datalek is binnen je organisatie zorgt dit niet voor problemen omdat de gegevens niet meer gezien worden als persoonsgegevens.
- Gegevens kunnen zonder probleem bewaard worden.
- Gegevens kunnen zonder probleem gebruikt worden voor andere doeleinden zoals statistische of analytische doeleinden.
Wat is het verschil tussen data anonimiseren en pseudonimiseren?
Het grote verschil tussen anonimiseren en pseudonimiseren is dat gepseudonimiseerde gegevens weer inzichtelijk gemaakt kunnen worden en hierdoor naar een persoon kunnen leiden. Anonimisering is onomkeerbaar.
Bij pseudonimisering kunnen anoniem gemaakte gegevens weer inzichtelijk gemaakt worden met de juiste sleutel. Met de juiste sleutel is het dan ook weer mogelijk om een herleiding te maken naar een natuurlijk persoon. Bij anonimisering is het niet mogelijk om de originele gegevens nog te achterhalen. De versleuteling van deze gegevens is onomkeerbaar.
Daarnaast zijn gepseudonimiseerde gegevens voor de AVG nog steeds persoonsgegevens en zijn de AVG regels nog van toepassing. Geanonimiseerde gegevens zijn voor de AVG geen persoonsgegevens meer, waardoor er geen AVG regels van toepassing zijn.
Staat jouw organisatie op het punt om de strategie met betrekking tot het verwerken van persoonsgegevens te herzien? Neem dan vrijblijvend contact met ons op. Wij helpen je graag met het pseudonimiseren of anonimiseren van gevoelige data in je database of documenten.
Onze oplossingen
Veel van onze klanten zijn zich ervan bewust dat ze documenten ontvangen, opslaan, bewaren en verwerken, waarin persoonsgegevens zichtbaar zijn voor de gehele of een groot deel van de organisatie. Inmiddels zijn deze klanten ‘schoongelakt’ door de software van DataFactory of FileFactory haar werk te laten doen. Benieuwd naar de mogelijkheden? Neem dan contact met ons op.